Can you trust your data analytics? Use these tips to check your data integrity
By Rich Jansen, Senior Fellow, Life Cycle Engineering
In today’s new world of Big Data, the Internet of Things, and Industry 4.0, data analytics is a hot topic. There is tremendous activity in the manufacturing sector focused on harnessing all the operational data that is being collected to improve bottom-line business performance. The ultimate goal, of course, is to derive actionable insights from the data, insights that drive manual or automated responses. To support this, many analytical programs/software have reached the market to execute and visualize the analytical results. Data analytics is exciting and promising – if you’re confident in the quality of your data.
When planning to analyze your business data, you need to respect the saying "Gold in, gold out." Always validate the integrity of the data source prior to making decisions based upon its analysis. For example, if you are looking at a basic Pareto chart to identify the primary contributors to a metric, you need to ensure that the data is comprehensive before making decisions based upon the analysis, which in this case would not meet the acceptance threshold.
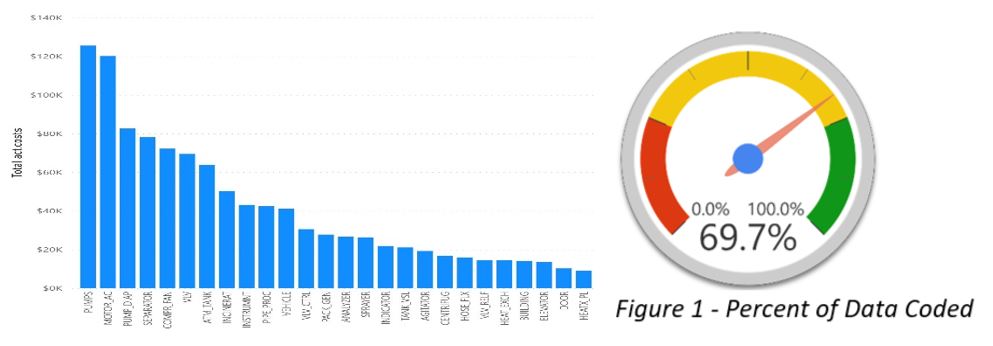
Have you validated the integrity of the data source prior to making decisions? Is the data comprehensive and is it accurate? Consider these areas when evaluating the quality of your data.
When evaluating maintenance work orders for cost information to determine which assets are driving the organization’s spending:

When evaluating maintenance work orders to compare performance against industry best practice benchmarks, consider the following:

How your CMMS is configured can also impact data integrity. Consider carefully how your CMMS is designed in these three areas:
Mandatory data fields
As mentioned earlier, configuring certain CMMS data fields to be mandatory for data entry can lead to the use of the “easiest entry” phenomenon. Using the first or last item on the list can result in corrupt data.
Default values
When default values are used in data fields, those fields are often overlooked during data entry. While this may seem to expedite data entry, it’s a recipe for corrupt information that could impact data analytics. If the data is almost always the default entry, then question whether the field should be used at all.
Showing the Plan at the time of Actual data entry
In many CMMS, it is common for the planned data (such as labor hours) to be included in the work order header (or even defaulted on the time entry screen.) This is like identifying the answer on a multiple choice test and then asking the user to simply select it. While the planner/scheduler should know the expected work duration of a job, and issue it accordingly, the value does not need to be on the order issued to the craftsperson. By not providing this value, you can expect a more un-biased, actual data entry.
In summary, to make good decisions based upon data, you need to be using good data. At a minimum, there should be some level of validation prior to data being used for decision making. The quality / integrity of the data is just as much a factor of data entry discipline as it is system configuration for intuitive and efficient use. When creating any data visualization, a representation of the data quality should always be a part, when possible, of how the results are provided to the decision makers.
Rich Jansen, a Senior Fellow with Life Cycle Engineering, has more than 20 years of experience in the areas of Quality Engineering, Manufacturing Engineering, and Maintenance. He specializes in optimizing the performance of highly automated, high-volume production processes in order to achieve maximum equipment utilization. You can reach Rich at rjansen@LCE.com.