One Skill That Takes Good Engineers to Great
By David J. Mierau, PE, CMRP, Life Cycle Engineering
If you’re good at root cause analysis, you can learn from your mistakes. If you’re great at root cause analysis, you can prevent mistakes from happening.
The concept of analyzing failures and tragedies to prevent them from occurring has been around for centuries. In fact, this is really the foundation of many legal systems and regulatory entities. When the United States government enacted the Pure Food and Drugs Act in 1906, and effectively created the Food and Drug Administration, this was in response to public health being negatively impacted by dangerous or misbranded food and drugs. People who had serious diseases needed scientifically tested medicines with controlled ingredients and dosages – not snake oil.
By the account of most sources, formal documented analysis of failures started occurring in the defense, automotive, aerospace and nuclear power industries in the mid twentieth century. Simple methods such as five whys progressed into more sophisticated methods such as Events & Causal Factor Analysis, Management Oversight and Risk Tree (MORT) and others. Today there are hundreds, if not thousands, of various methods utilized for root cause analysis across nearly every industry.
Engineers are classically trained in mathematics and physical sciences. We are taught to evaluate, analyze and calculate. Most current engineering curricula contain a course that includes problem solving, which is often intertwined with root cause analysis. However, to be most effective at root cause analysis you need to combine process and theory with application knowledge. You can understand inside and out the root cause analysis fault tree methodology, but without working knowledge of the equipment or situation being analyzed, or access to personnel with this experience, your results will not be comprehensive or effective.
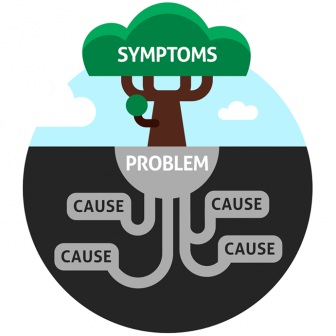
Often with root cause analysis, investigators are focused on the “who” and “what”. These areas can be categorized into “human” and “physical” causes of failures.
From a human perspective, we look at the ways people make mistakes and errors. Maybe an operator forgot to adjust the speed of a conveyor belt when the production line changed from one product to another. Maybe a mechanic used a standard socket wrench instead of a torque wrench to tighten the bolts on a machine during a repair. These are human root causes and disciplinary or training actions need to be taken, right? Not necessarily!
For physical failures, things are often considered more obvious. My washing machine stopped working this morning. I removed the front access panel and discovered the drive belt was broken between the electric motor and wash drum pulleys. Therefore, the root cause of the washing machine not working was a broken drive belt, right? All I need to do is replace the belt and restart, right? No, and no.
Most human and physical causes are actually causal factors, or proximate causes. They are the events that occurred immediately before the main event or undesired outcome. It is true that if I somehow knew the belt on my washing machine was going to fail just before it did (through vibration monitoring maybe), that I could have replaced it and prevented the unexpected failure. However, what if I told you that the washing machine was only five months old, or that morning someone had loaded 15 heavy bath towels into the machine? Now it seems my solution of just replacing the belt every four months does not seem reasonable, since I’m only addressing the physical issue.
Driving down several “layers” of causes below human and physical proximate causes will eventually get you to a root cause. The root cause is what created the proximate cause and subsequent undesired outcome. Typically, there is only one or very few root causes. These can be categorized as “latent” causes, or the underlying issues leading up to a failure. If these are eliminated, the situations that created the human and physical proximate causes would not have arisen.
In the example of the broken washing machine belt, too many towels in the machine created excess weight that the belt could not handle and it snapped. Why were too many towels loaded into the machine in the first place? There was a lack of operator knowledge. When the big box store delivered and installed the machine, they did not have a turnover checklist item to train the owner. This is an issue that could be categorized as “lack of procedure/checklist”. If an administrative control was in place to review the manual with the owner, including loading limitations, fewer towels would have been loaded into the machine and therefore no overload or broken belt. Another better solution may be to change the machine design to include a load sensor so at the beginning of a wash cycle an alarm sounds to remove some of the wash load (some washing machines today have load sensors).
Of course in today’s complex world of operations with ever-growing daily responsibilities for the typical worker, the solutions cannot always be to add more administrative controls and safeties. However, for critical situations where people’s lives and millions of dollars are at stake, these types of solutions are justified. If your company is trying to be as efficient as possible and is working to drive out unplanned downtime, understanding and mitigating latent causes is a big part of getting there.
Ultimately, systems and processes need to be proactively evaluated and designed in ways that eliminate or mitigate common latent failure causes. Great engineers and technicians can take their knowledge of machine design, combine that with their operating experience, and apply these to predict human and physical proximate causes. Digging deeper to understand the potential latent causes of these proximate causes will ultimately lead to the most effective failure prevention measures, and the safest, most reliable solutions.
References:
- United States Department of Energy Guideline DOE-NE-STD-1004-92: Root Cause Analysis Guidance Document
- DPST—87-209: User’s Guide for Reactor Incident Root Cause Coding Tree, E.I. du Pont de Nemours & Co.
- Maintenance Engineering Handbook, 8th Ed., K. Mobley
- History of the United States Food and Drug Administration: www.fda.gov
David Mierau is a Principal Consultant and Senior Reliability Engineering Subject Matter Expert with Life Cycle Engineering (LCE). David is a licensed Professional Engineer, a CMRP, and a Certified Lean-Six Sigma Green Belt. You can reach him at dmierau@LCE.com.
© Life Cycle Engineering